Kubernetes + GPU Setup
For Kubernetes clusters with GPU nodes. This is the most advanced setup: if you're not already running K8s, start with Docker instead.
Who this is for
You run a Kubernetes cluster with NVIDIA GPU nodes (on-prem, cloud, or hybrid). You want Immich Memories as a scheduled workload with GPU-accelerated encoding and optional music generation pods.
Architecture
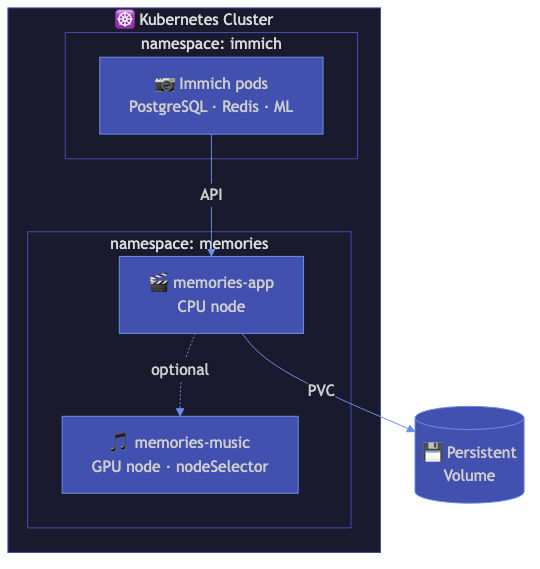
┌─────────────────────────────────────────────────────┐
│ Kubernetes Cluster │
│ │
│ ┌──────────────────────────────────────────────┐ │
│ │ namespace: immich-memories │ │
│ │ │ │
│ │ ┌────────────┐ ┌────────────┐ │ │
│ │ │ Deployment │ │ Job │ │ │
│ │ │ (UI/API) │ │ (batch │ │ │
│ │ │ port 8080 │ │ generate) │ │ │
│ │ │ GPU: 1 │ │ GPU: 1 │ │ │
│ │ └────────────┘ └────────────┘ │ │
│ │ │ │
│ │ PVCs: config (1Gi), cache (20Gi), │ │
│ │ output (50Gi) │ │
│ └──────────────────────────────────────────────┘ │
│ │
│ ┌─────────────────┐ │
│ │ GPU Operator │ (manages nvidia.com/gpu) │
│ └─────────────────┘ │
└─────────────────────────────────────────────────────┘
│
┌────┴─────────┐
│ Immich server │ (same cluster or external)
└──────────────┘
Prerequisites
- NVIDIA GPU Operator installed:
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm repo update
helm install gpu-operator nvidia/gpu-operator \
--namespace gpu-operator \
--create-namespace
- Storage class available for PersistentVolumeClaims
- Immich accessible from the cluster (same namespace, different namespace, or external)
Deploy with Kustomize
The manifests live in deploy/kubernetes/ in the repo:
cd deploy/kubernetes
# Create the secret
cp secret.yaml.example secret.yaml
# Edit with your Immich URL and API key
vim secret.yaml
# Deploy
kubectl apply -k .
Or apply individually:
kubectl apply -f namespace.yaml
kubectl apply -f secret.yaml
kubectl apply -f configmap.yaml
kubectl apply -f pvc.yaml
kubectl apply -f deployment.yaml
kubectl apply -f service.yaml
Access the UI
kubectl port-forward -n immich-memories svc/immich-memories 8080:80
Open http://localhost:8080. For production, set up an Ingress with your existing ingress controller.
GPU resource requests
The deployment requests 1 NVIDIA GPU. Adjust in the deployment manifest:
resources:
requests:
nvidia.com/gpu: "1"
memory: "4Gi"
cpu: "2"
limits:
nvidia.com/gpu: "1"
memory: "8Gi"
cpu: "4"
Node selection
Pods schedule on nodes with nvidia.com/gpu.present=true (set by the GPU Operator). If your cluster uses different labels:
nodeSelector:
nvidia.com/gpu.present: "true"
# Or your custom label:
# gpu-node: "true"
For music generation pods (MusicGen/ACE-Step), you might want separate node affinity rules to schedule on nodes with more VRAM.
Batch jobs
Run one-off generation without the UI:
kubectl apply -f job.yaml
kubectl logs -n immich-memories -f job/immich-memories-generate
Storage
Default PVC sizes:
| PVC | Size | Purpose |
|---|---|---|
| Config | 1Gi | Config files, analysis cache database |
| Cache | 20Gi | Downloaded video files, thumbnails |
| Output | 50Gi | Generated videos |
The cache PVC holds cache.db (analysis scores from all previous runs). This is the most valuable volume: losing it means re-analyzing your entire library. Back it up:
kubectl exec -n immich-memories deployment/immich-memories -- \
immich-memories cache backup /output/cache-backup.db
Secrets management
Don't commit plain secrets to git. Use sealed-secrets or your cluster's secret management:
kubeseal --format=yaml < secret.yaml > sealed-secret.yaml
kubectl apply -f sealed-secret.yaml
Health monitoring
The /health endpoint returns JSON:
{
"status": "ok",
"immich_reachable": true,
"last_successful_run": "2025-12-15T10:30:00",
"version": "0.2.0"
}
Status is ok when Immich is reachable, degraded otherwise. The deployment includes liveness and readiness probes hitting this endpoint.
Point your monitoring (Uptime Kuma, Prometheus blackbox exporter, etc.) at /health on port 8080.
What works / what doesn't
Same as the Linux + NVIDIA setup: NVENC encoding, CUDA face detection, Taichi GPU titles. The Kubernetes layer adds scheduling, scaling, and PVC-based storage.
Performance
Same as bare-metal Linux + NVIDIA. Kubernetes overhead is negligible for this workload. The bottleneck is GPU encoding speed and Immich API download throughput, not container orchestration.
Further reading
- Terraform deployment for infrastructure-as-code provisioning
- Kubernetes manifests for detailed manifest reference