Linux + NVIDIA GPU Setup
For Linux servers with NVIDIA GPUs. Docker with nvidia-container-toolkit for NVENC encoding, CUDA face detection, and optional AI music generation.
Who this is for
You have a Linux server (Ubuntu, Debian, Fedora) with an NVIDIA GPU (GTX 1060 or newer). You want hardware-accelerated encoding and optionally want to run MusicGen or ACE-Step for AI-generated background music.
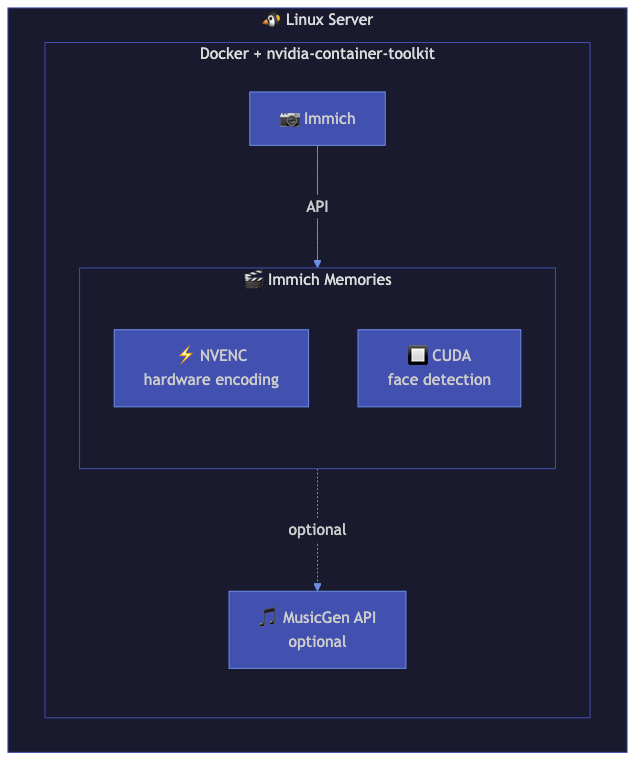
Architecture
┌──────────────────────────────────────────────────────┐
│ Linux Server (NVIDIA GPU) │
│ │
│ ┌────────────────────────────────────────────────┐ │
│ │ Docker (nvidia-container-toolkit) │ │
│ │ │ │
│ │ ┌──────────────────┐ ┌────────────────────┐ │ │
│ │ │ Immich Memories │ │ MusicGen API │ │ │
│ │ │ NVENC encoding │ │ (optional) │ │ │
│ │ │ CUDA analysis │ │ port 8000 │ │ │
│ │ │ port 8080 │ │ │ │ │
│ │ └──────────────────┘ └────────────────────┘ │ │
│ └────────────────────────────────────────────────┘ │
│ │ │
│ ┌────────┴─────────┐ │
│ │ Immich server │ │
│ └──────────────────┘ │
└──────────────────────────────────────────────────────┘
Prerequisites
Install the NVIDIA container toolkit:
# Ubuntu/Debian
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | \
sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker
Verify with: docker run --rm --gpus all nvidia/cuda:12.4.0-base-ubuntu22.04 nvidia-smi
Docker Compose
services:
immich-memories:
image: ghcr.io/sam-dumont/immich-video-memory-generator:latest
container_name: immich-memories
ports:
- "8080:8080"
volumes:
- immich-memories-config:/home/immich/.immich-memories
- ./output:/app/output
environment:
IMMICH_URL: "${IMMICH_URL}"
IMMICH_API_KEY: "${IMMICH_API_KEY}"
restart: unless-stopped
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
limits:
memory: 8G
volumes:
immich-memories-config:
.env file
IMMICH_URL=http://immich-server:2283
IMMICH_API_KEY=your-api-key-here
What works
- NVENC encoding: hardware-accelerated H.264/H.265 encoding. The
hardware.backendauto-detects NVIDIA and uses NVENC automatically. - CUDA face detection: faster face detection using GPU compute.
- Taichi GPU title renderer: full particle effects, animated globes, gradient backgrounds using the NVIDIA GPU.
- AI music generation: if you run a MusicGen or ACE-Step server alongside, configure it in the
musicgenorace_stepconfig sections. - All memory types and features: everything works with GPU acceleration.
What doesn't work
- LLM content analysis on consumer GPUs: vision-language models like Qwen2.5-VL-7B need ~14 GB VRAM at full precision. The 8-bit quant fits on an RTX 3060 12 GB, but an RTX 3060 8 GB or lower won't cut it. Use Ollama or a separate LLM server if VRAM is tight.
Performance expectations
On an RTX 3060 12 GB (Linux, Docker):
| Clips | Resolution | Time |
|---|---|---|
| 15 | 1080p | ~3 min |
| 30 | 1080p | ~5 min |
| 30 | 4K | ~9 min |
| 50 | 1080p | ~8 min |
NVENC encoding is roughly 3x faster than CPU libx264 at equivalent quality. The bottleneck shifts from encoding to downloading clips from Immich once you have GPU acceleration.
Adding LLM analysis
Run Ollama with GPU support alongside Immich Memories:
docker run -d --gpus all -p 11434:11434 --name ollama ollama/ollama
docker exec ollama ollama pull qwen2.5-vl
Then add to your Immich Memories config:
advanced:
llm:
provider: ollama
base_url: http://ollama:11434
model: qwen2.5-vl
content_analysis:
enabled: true
Adding AI music
MusicGen or ACE-Step servers need their own GPU allocation. If you have a single GPU, time-share it: generate music first, then encode video. If you have multiple GPUs, dedicate one for music generation.
Configure in config.yaml:
advanced:
musicgen:
enabled: true
base_url: http://musicgen-server:8000
Tips
- Check GPU detection: run
docker exec immich-memories immich-memories hardwareto verify GPU detection inside the container. - Multi-GPU: set
hardware.device_indexin config to select a specific GPU (0-indexed). - VRAM monitoring: watch
nvidia-smiduring generation. Peak VRAM usage is about 2-3 GB for encoding, 1-2 GB for Taichi title rendering. - Headless Linux: the CLI works fully on headless servers. Use
immich-memories generateinstead of the UI if you don't need a browser.